Claude Is My Second Contributor
Our git stats show 6 contributors. One of them is an AI. Here's what the commit history looks like, not the marketing version.
TL;DR
| What | Details |
|---|---|
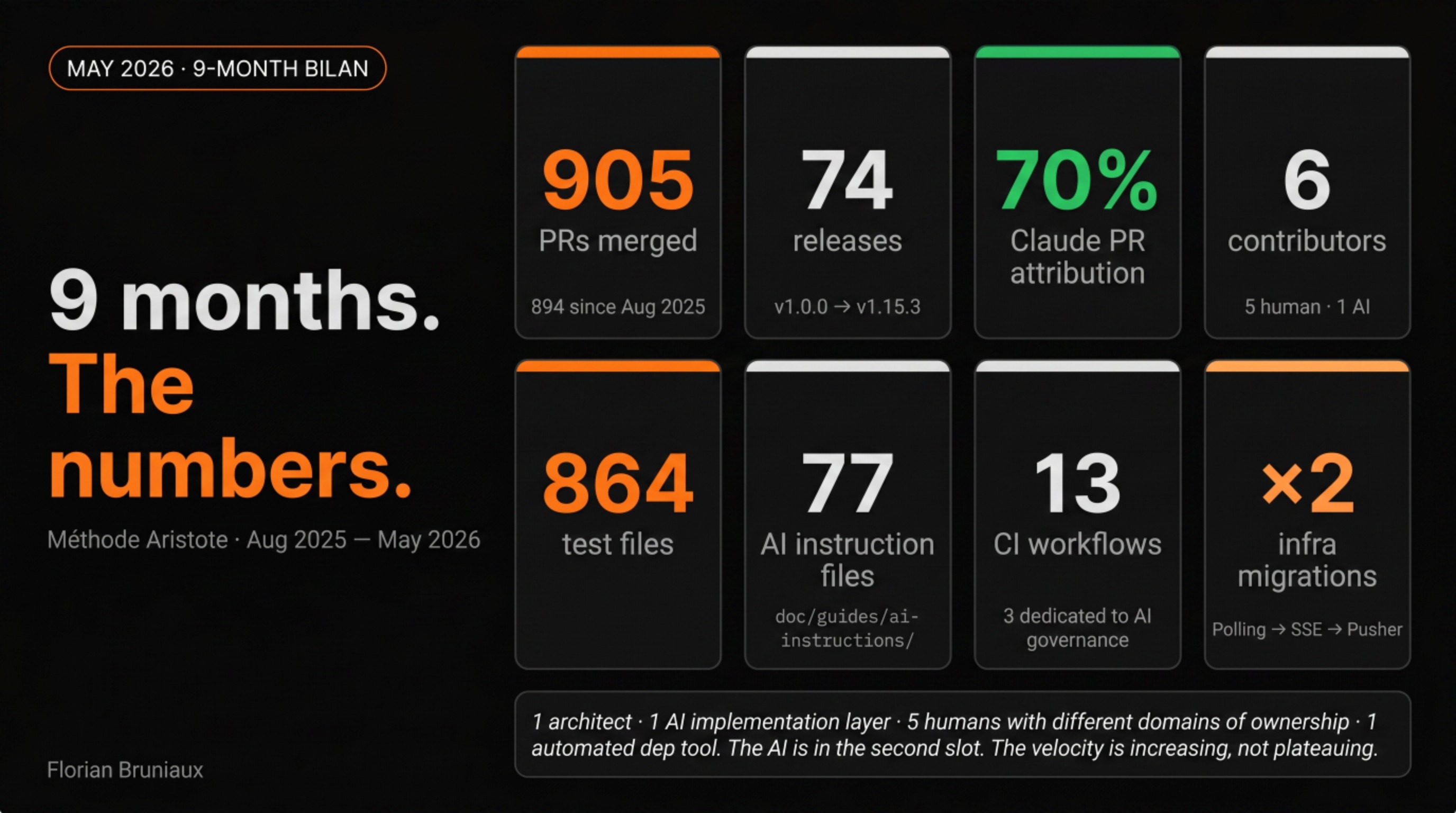
| The numbers (May 2026) | 905 PRs merged. 74 releases. 9 months since v1.0.0. |
| Claude’s share | 70% of PRs carry a Claude attribution in the body. Second contributor by any measure. |
| What Claude does | Scaffolding, refactoring, test generation, documentation, repetitive patterns. The AI config system itself. |
| What humans still do | Architecture decisions, complex debugging, product judgment, security review. Infrastructure trade-offs. |
| How it changed | From one handwritten CLAUDE.md to 77 AI instruction files, 13 CI workflows, 3 dedicated to AI governance. |
| Open source output | Claude Code Ultimate Guide (430K+ lines), CC Bridge, CCBoard, RTK contributions. |
| The honest assessment | Claude is not a developer. Claude is the most productive tool I’ve ever used. The distinction still matters. |
Started as a February 2026 snapshot. Updated to May 2026 with current data.
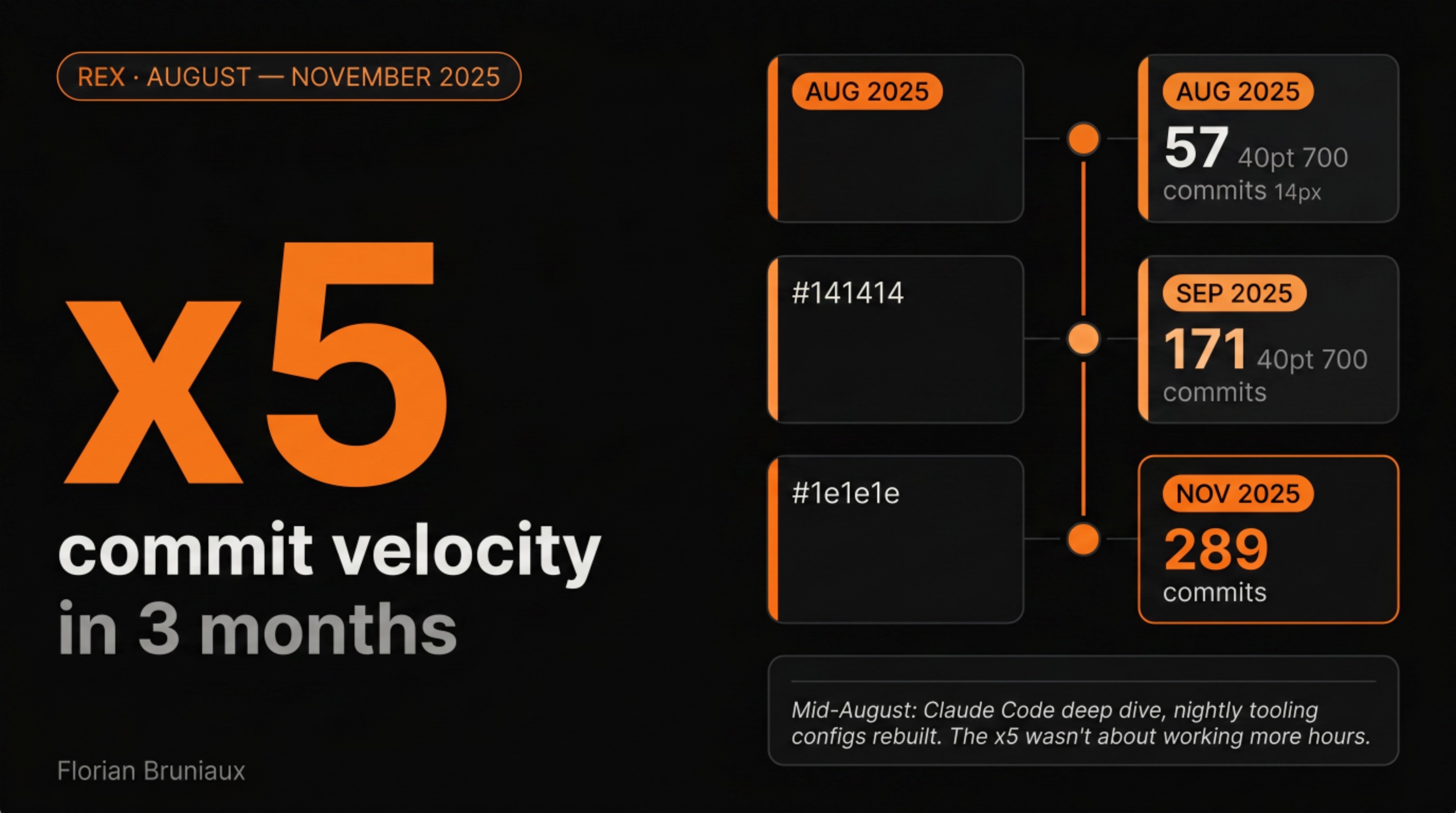
Our git history shows 6 contributors to the Méthode Aristote repository. One of them is an AI.
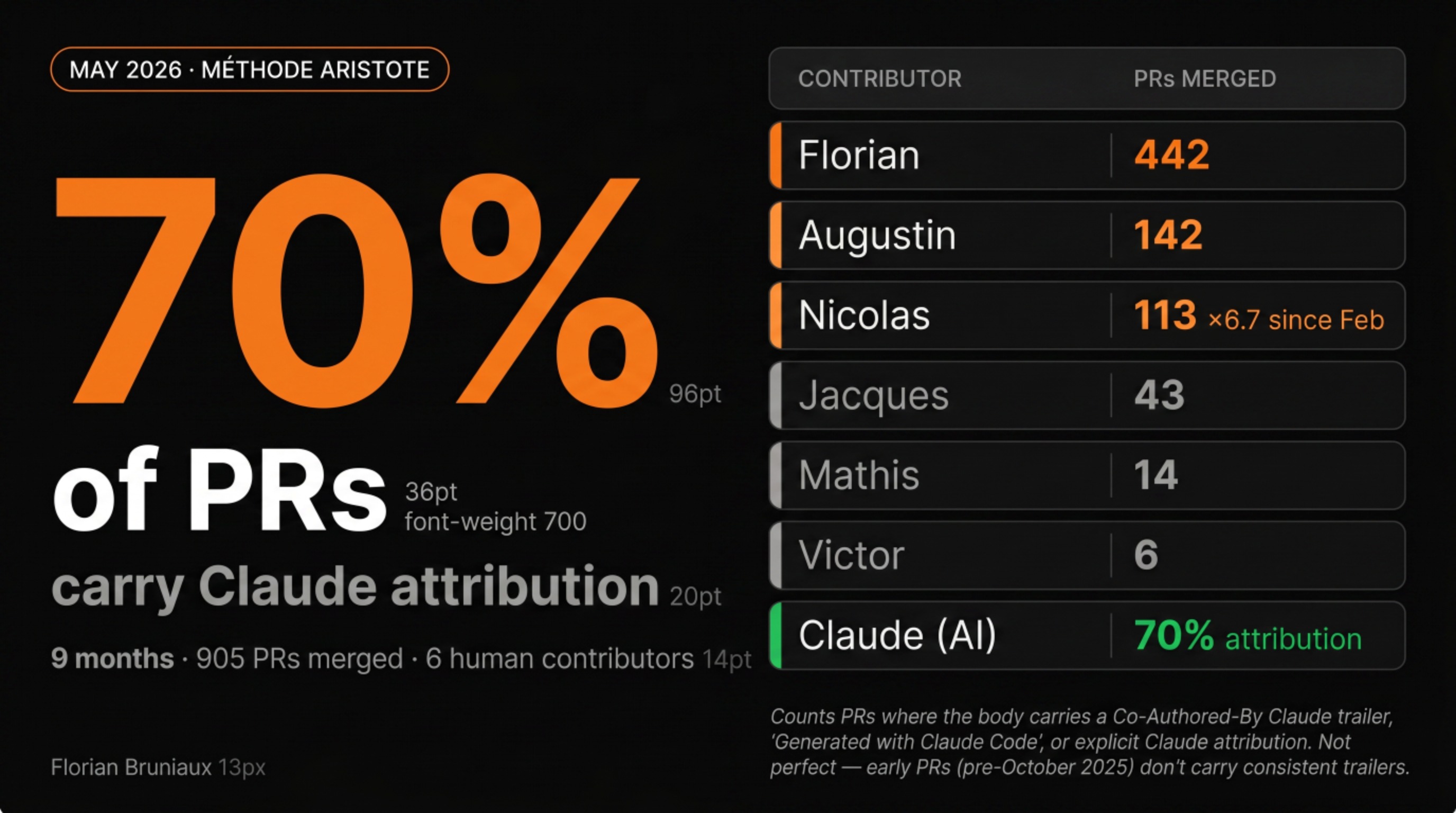
70% of merged PRs carry a Claude attribution in the body. 905 pull requests total, 894 since the project started in August 2025. By that metric, Claude is the most consistently present contributor to this codebase.
That’s the hook. Here’s the honest version.
What the commit stats measure
The 70% figure counts PRs where the pull request body contains a Co-Authored-By Claude trailer, a “Generated with Claude Code” reference, or an explicit Claude attribution. It’s not a perfect count: attribution wasn’t standardized from day one, and early PRs (pre-October 2025) don’t carry consistent trailers, but it’s verifiable from the GitHub API, which makes it more reliable than trying to attribute commits after the fact.
What the 70% includes:
- New service and repository files following the 3-tier pattern (same structure, different domain logic)
- Unit test generation for established patterns
- Refactoring passes across many files simultaneously
- Documentation generation and maintenance
- The AI instruction system itself: 77 files describing how to work with Claude on this project
What it doesn’t capture: the decisions about what to build, the architecture choices, the debugging sessions where the behavior was wrong in a way Claude couldn’t see, and significant chunks of code that humans wrote independently without attribution.
PR count is a cleaner signal than commit count for this kind of analysis. One Claude session might produce 3 files and show up as one commit. PRs represent units of shipping, reviewed, validated, and merged. 70% of those units carried Claude participation.
What Claude does
Scaffolding new patterns
The 3-tier architecture at Méthode Aristote (Router = validation, Service = business logic + permissions, Repository = CRUD only) is consistent across 70+ services. When I need a new service, the entire chain is replicable: tRPC router with Zod validation, service layer with typed inputs and permission checks, repository with Prisma queries.
Claude knows this pattern because it’s in the codebase and in the CLAUDE.md context. Creating the fifteenth service with this pattern is work Claude does well and fast. Creating the first one required the architectural decision that Claude wasn’t part of.
Test generation
In January 2026: services (45 tests), repositories (174 tests), adapters (64 tests), all in focused sessions over a few weeks. Writing unit tests for established patterns is exactly the kind of repetitive, well-defined work where AI output is reliable and fast. By May 2026, the repo has 864 test files across all layers.
The tests needed review. Some edge cases were missed. Some assertions were semantically correct but didn’t test the right thing. Human review caught those. The baseline generation was Claude’s.
Refactoring at scale
Code duplication from 55% to 8%. That’s a lot of files to touch, a lot of patterns to identify and consolidate. Claude handles the mechanical application of a refactoring pattern across many files faster than any human workflow I’ve found. The identification of what to refactor (which patterns were worth consolidating, which apparent duplication was intentional) was human judgment.

Documentation
The Claude Code Ultimate Guide: 430,000+ lines across 1,000+ files. Maintained with AI assistance because maintaining it manually at that volume would be impossible. Structure, editorial decisions, examples from actual production experience: all mine. Claude generates from notes and rough drafts.
The AI instruction system itself
The 77-file system in doc/guides/ai-instructions/ (rules, modules, developer profiles, skill indexes) is largely Claude-generated from design sessions. It describes how to work with Claude on this project. It grew from a single CLAUDE.md file to a structured documentation layer with its own tests and CI validation. More on that below.
What humans still do
Architecture decisions
The 3-tier architecture exists because I decided it should. The choice to use Neon PostgreSQL instead of Supabase, tRPC instead of REST, Clerk for authentication: those trade-offs weren’t Claude’s to make.
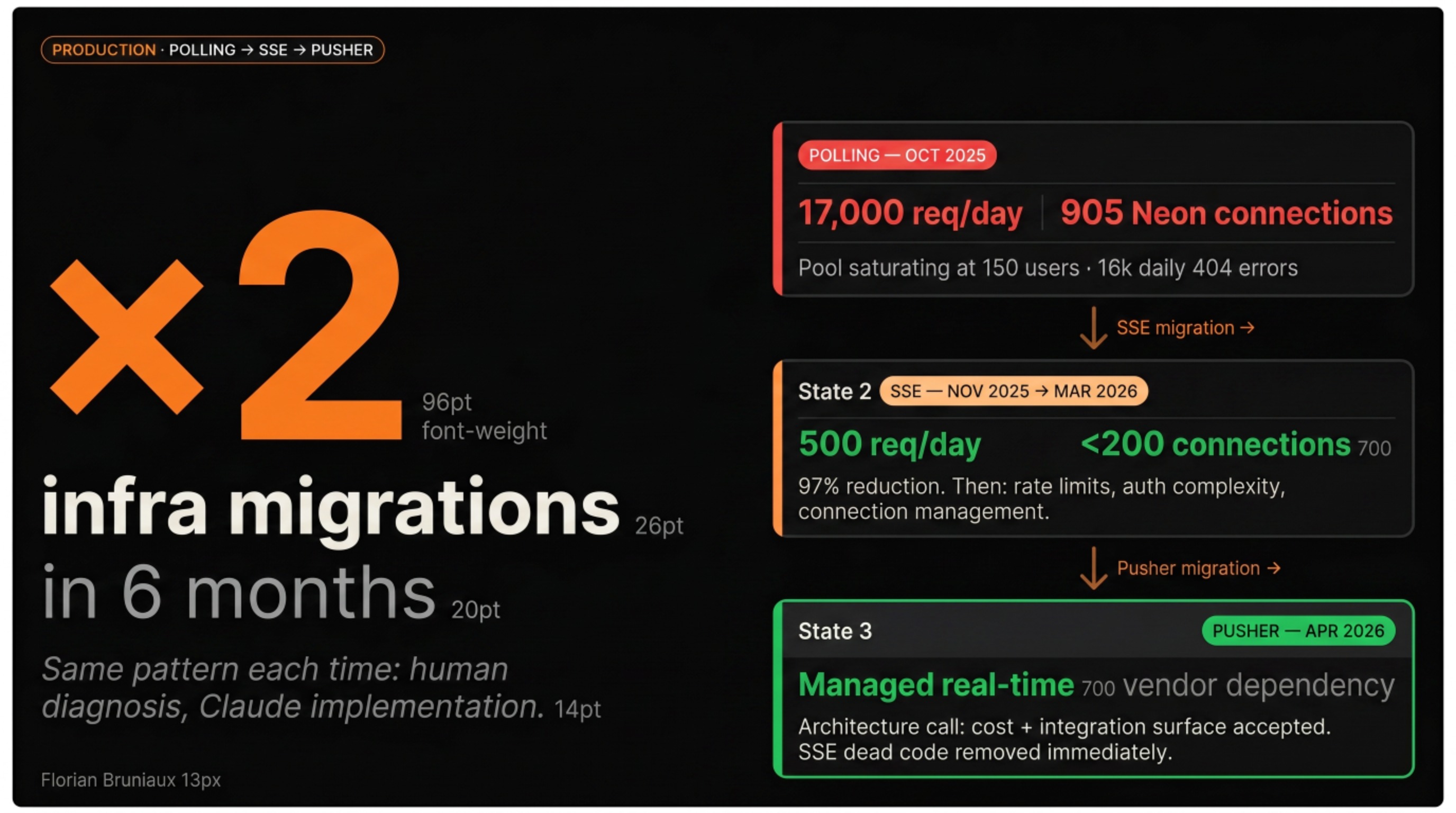
When the initial polling approach was generating 17,000 requests per day and saturating the Neon connection pool at 905 connections, the diagnosis came from reading logs, correlating Sentry events, and understanding the connection lifecycle. Claude helped implement the SSE migration once the hypothesis was formed. The hypothesis took human work to form.
Then, several months later, when SSE had its own limitations (rate limits, auth complexity, long-lived connection management), the decision to move to Pusher was another architecture call. Not obvious. There’s a real cost to adopting a managed real-time service: vendor dependency, pricing model, integration surface. We moved anyway. Claude implemented the migration across the codebase once the decision was made.
Complex debugging
The 20,000 orphan streams cleaned up in December 2025 didn’t announce themselves. Debugging why streams were orphaned required reading logs, correlating Sentry events, understanding the connection lifecycle. Claude was useful once the hypothesis was formed. Forming the hypothesis was the hard part.
Security review
The IDOR fix (ANY → TEAM/ASSIGNED permissions) that resolved 8,600+ Sentry events. The CVE-2025-55182 patch. The pre-push security hooks that run on every commit. These required understanding attack surfaces, thinking adversarially, knowing what the permission model was supposed to enforce. Claude operates within the security model. Building and reviewing it is human work.
Product judgment
What to build next, what user feedback means architecturally, when a feature request is actually a UX symptom with a different fix, when to ship and when to hold.
Claude can implement any feature I describe, but that’s not the same as knowing which one matters.
The infrastructure kept evolving
Between February and May 2026, two things happened that aren’t visible in the commit count.
The real-time stack changed again
The February 2026 story ended with the SSE migration: polling (17,000 req/day) → SSE (under 500). That was the winning state in February. By March, SSE was replaced by Pusher. The migration was complete by mid-April, the dead code removed immediately after.
The Pusher decision involved real trade-offs: switching from a self-hosted SSE implementation to a managed third-party service means a recurring cost, a new integration surface, and a dependency on an external vendor. These are architecture calls I made. Claude implemented channel auth, subscription management, and error handling across the full stack once the approach was set. Pusher was introduced in v1.7.1 on March 10, the migration was complete by April 17, 38 days from decision to dead code removed.
The pattern repeats across every infrastructure change: human decision about what to adopt and why, Claude handling the mechanical implementation of that decision across the codebase.
The CI grew AI-specific gates
In August 2025, there was one workflow: a handwritten claude.yml copied from the GitHub marketplace. In May 2026, there are 13 workflows totaling ~2,700 lines of YAML. Three of them are specifically about AI governance:
claude-code-review.yml(87 lines): runs a Claude Code review on every pull request automaticallyai-config-check.yml(83 lines): validates that the AI instruction system hasn’t drifted from the actual codebaseclaude.yml(50 lines): the original Claude Code general workflow
The ai-config-check.yml workflow runs a tool called ctxtest (13 facts about the codebase that should be verifiably true) (Next.js version, database patterns, team conventions). If the AI context description and the actual codebase diverge, CI fails. It’s a test suite for the instructions we give to Claude, not for application code. CI was already enforcing code quality; it now also enforces AI context quality.
The AI config became infrastructure
In February 2026, the CLAUDE.md approach was: one big file, maintained manually, updated when things broke. By May 2026, it’s a different system.
doc/guides/ai-instructions/ contains 77 files. Rules organized by domain (architecture, code conventions, git workflow, security, React patterns, TypeScript, TDD). Modules with reference material for specific contexts (Knock notifications, Storybook conventions, business domain). Five developer profiles, one per human on the team, that configure which rules apply to which person and which files they’re allowed to modify.
The total is ~5,900 lines of AI instruction documentation, maintained as a structured system with its own validation. When a developer profile says Augustin owns the tutoring flow, the pre-commit hook enforces that Claude can’t modify those files for another developer’s session without flagging it. In April 2026, the AI context quality score reached A+ (150/150 on the internal eval). That’s a number generated by pnpm ai:validate, which checks completeness, accuracy, and freshness of the AI instruction system against the actual codebase.
The loop: humans write the rules, Claude operates within them, CI enforces that the rules stay accurate, the system self-documents via pnpm ai:sync. The maintenance burden went from “update CLAUDE.md manually when something breaks” to “pass the CI gate.”
The open source output
Beyond Méthode Aristote, I shipped 9 separate projects during the same period. Not sequentially: in parallel, while the main platform was running. The pattern is the same across all of them.
The AI tooling layer
Claude Code Ultimate Guide (GitHub) (22K lines, 204 templates, 271 quiz questions, a security threat database tracking 15 CVEs and 655 malicious skills): the field moves fast enough that maintaining this manually would be a full-time job. Claude generates from notes and rough drafts. Structure, editorial decisions, examples from production: mine.
ctxharness (GitHub) is the tool that came directly out of the Méthode Aristote ctxtest workflow. Your CLAUDE.md says Prisma 7.5. Your package.json has ^7.7.0. Your agent is reasoning against stale facts on every session, silently. ctxharness catches it: 20 extractors, 15 scanners, 3 layers of context engineering testing. Built because I had the problem first.
CCBoard (GitHub) is a real-time TUI and web dashboard for monitoring Claude Code sessions. Token consumption, response times, session history, hook execution, MCP server health. Built in Rust. The monitoring infrastructure I wanted but didn’t have.
cc-sessions is a fast Rust CLI to search, browse, and analyze Claude Code session history. I wouldn’t have touched a Rust project without the Claude Code workflow making it viable.
cc-copilot-bridge (GitHub) solves a specific problem: ran out of Claude credits, had Copilot credits unused. The bridge lets you route Claude Code through your Copilot subscription. Architecture decision and problem identification: mine. Implementation: Claude.
Claude Cowork Guide (GitHub) covers the non-coder side, 28 business workflows and 70 copy-paste prompts for Claude Desktop users. HR, finance, marketing, sales. Complementary to the developer guide, different audience entirely.
The developer tools
dep-scope answers the question that Knip and Depcheck don’t: not just whether a package is used, but which symbols, how often, across how many files, and whether a native alternative would let you delete the dependency entirely. 195 native alternative mappings, 371 tests, LLM migration prompt generation that pipes directly into Claude Code. The problem existed long before I had the workflow to build the tool.
StarMapper (GitHub) lets you paste a GitHub repo URL and get a world map of every developer who starred it. No login, just a URL and a GitHub token. Built it in a weekend because the data was interesting and the workflow made it fast enough to be worth attempting.
RTK is Patrick’s project. A CLI proxy that reduces token consumption 60-90% on dev commands by filtering noise before it reaches the model. When I saw the approach, I became a contributor. RTK is now in my daily workflow and mentioned elsewhere in this article as Layer 1 of the context engineering stack.

Is Claude a developer or a tool?
The question surfaces regularly. The answer I’ve landed on is that the distinction is less useful than it seems.
Claude doesn’t have goals or a stake in the product working. Previous approaches that failed only matter if they’re still in the context window. A debugging session going in circles doesn’t frustrate it, because frustration requires caring about the outcome.
These aren’t limitations to overcome, they’re the nature of what it is. And what it is turns out to be extremely useful for a specific kind of work: well-defined implementation work where the pattern is clear, the scope is bounded, and the output can be reviewed.
The 70% PR attribution is real. What it means is that a meaningful portion of the implementation work on this codebase was produced by an AI working within specifications and patterns that humans defined. That changes what individual developer productivity looks like. It doesn’t change what judgment, experience, and product sense are worth.
The honest accounting
9 months of production development, as of May 2026:
- 905 PRs merged (894 since August 2025). 408 in the last 3 months, against 497 in the first seven, roughly equivalent output in less than half the time. April 2026 was the single most active month at 178 PRs. The velocity is increasing, not plateauing.
- 74 releases, v1.0.0 on August 27, 2025 to v1.15.3 on May 11, 2026
- 6 human contributors by commit count: Florian (1,338), Nicolas (455, ×6.7 since February), Augustin (237), plus Jacques, Mathis, Victor
- 1 AI contributor: 70% PR attribution (634 of 905), no separate commit authorship, present in the majority of shipped work
- 13 CI workflows (~2,700 lines of YAML), 3 dedicated to AI governance
The pattern that hasn’t changed: Claude handles the implementation work that fits a defined scope. Humans handle everything that requires judgment about what to build next or how to resolve a system-level conflict.
What did change is the scope of “defined.” The 3-tier pattern was defined early and Claude scaffolds it reliably. The AI instruction system grew from one file to 77, and Claude now generates and maintains it from design sessions. The CI is now partially self-governing: AI reviews each PR, and the AI context itself has a CI gate that fails if it drifts from reality. The infrastructure for working with Claude has become as substantial as the application infrastructure.
The GitHub stats say 7 contributors. The practical breakdown is 1 architect, 1 AI implementation layer, 5 humans with different domains of ownership, and 1 automated dependency tool. The AI is in the second slot. What that slot actually contains is implementation throughput at a scale that changes what’s possible for the humans who set the direction. What changed is where my attention goes: less time generating boilerplate, more time on the problems where experience and judgment actually matter.
Stats from the Méthode Aristote repository as of May 12, 2026. PR attribution measured via GitHub API (Co-Authored-By and Claude Code body mentions). Open source projects available at github.com/FlorianBruniaux. For the mechanics behind Claude Code and the configuration system, Claude Code Under the Hood covers the architecture.